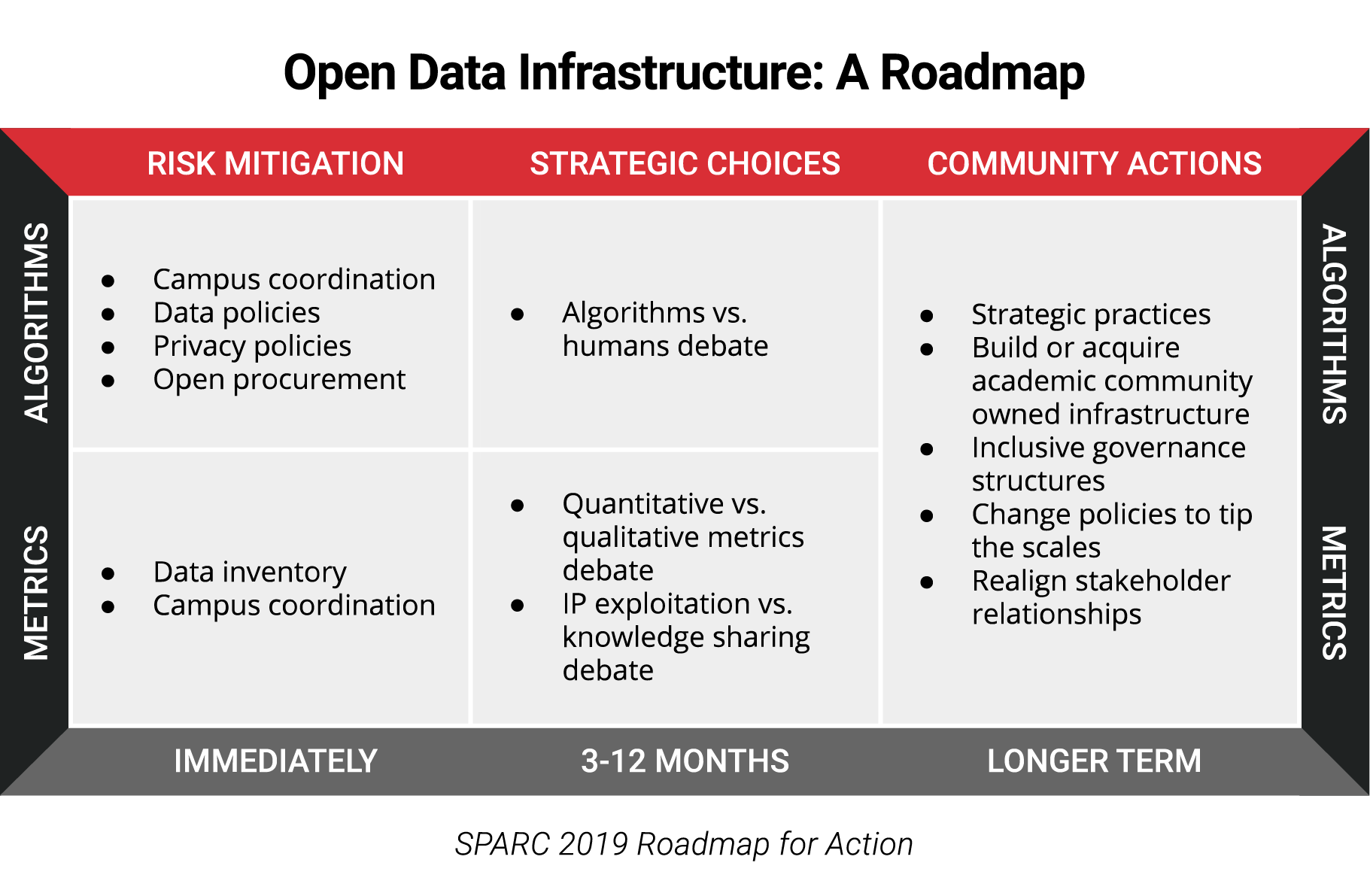
Any proposed solutions must address the different challenges posed by the adoption of data analytics in research, teaching, and student life. The menu of proposed solutions is based on two complementary organizing principles. The first, already delineated in the previous section, distinguishes between metrics and algorithms. The second organizing principle distinguishes between three types of action, based on the level of control that academic institutions have. We have called the three categories respectively risk mitigation, strategic choices, and community actions. Each category is summarized below, then discussed in more detail in the remainder of the document.
-
Risk Mitigation. Under risk mitigation actions, we include steps that individual academic institutions can take to mitigate, if not eliminate altogether, some of the risks posed by the collection of data and deployment of data analytics. These actions often can be executed relatively quickly, require a varying but manageable amount of investment and expense, and achieve a tangible impact on how data is treated within institutions. Examples of these actions include the establishment of coordination mechanisms on campus, revision of data policies, and the adoption of open procurement policies.
-
Strategic Choices. Actions in this category require a thorough debate of issues that do not have easy answers. Questions including what metrics to use, the extent to rely on artificial intelligence, and the extent to which to prioritize IP exploitation require a much deeper analysis of both pros and cons, as well as a realistic assessment of what is culturally acceptable in terms of actions. Individual Institutions will legitimately have very different responses to these choices according to their values and missions, and will need to engage a wide variety of stakeholders. These debates are often centered around cost-benefit analyses of widely adopting data analytics tool.
-
Community Actions. Community-based, structural actions are possible send-game solutions that may allow groups of institutions to retake control of their data infrastructure. This category includes different scenarios, largely depending on the resources available. There are possible trade-offs between speed of rollout (which could be achieved by acquiring existing infrastructure) and amount of investment (since building the infrastructure from the ground up may prove more cost effective). Also included in this category would be the pooling of intellectual property and text and data mining of research to develop insights that are valuable to industry and financial institutions, or negotiating collective deals with better terms, pursuing policy actions, and realigning stakeholder relationships.
These categories are directional, rather than prescriptive, as we actively support the availability of a wide array of infrastructures. These can be built from scratch by the academic community, can be acquired and grown, and they can also be managed by commercial vendors and/or funding bodies willing to work with the academic community on innovative joint governance models. In turn different institutions will make different choices on which initiatives to support, how, and when.