Compiling a map of all the products and services that the three leading research data analytics vendors (Clarivate, Digital Science, Elsevier) market outside libraries is inherently a best effort exercise (Exhibit 7). Many of the companies or businesses within each company rely on a large trove of data and, effectively, repackage this data to serve as many different purposes as possible. In other words, only ingenuity limits what can be sold. The Elsevier and Clarivate offerings tend to rely heavily on data they first collect as part of their library services: Scopus and Web of Science represent significant foundations for many of the services and products offered respectively by Elsevier and Clarivate.
Exhibit 7
A map of the data tools and services offered by Clarivate, Digital Science, and Elsevier.
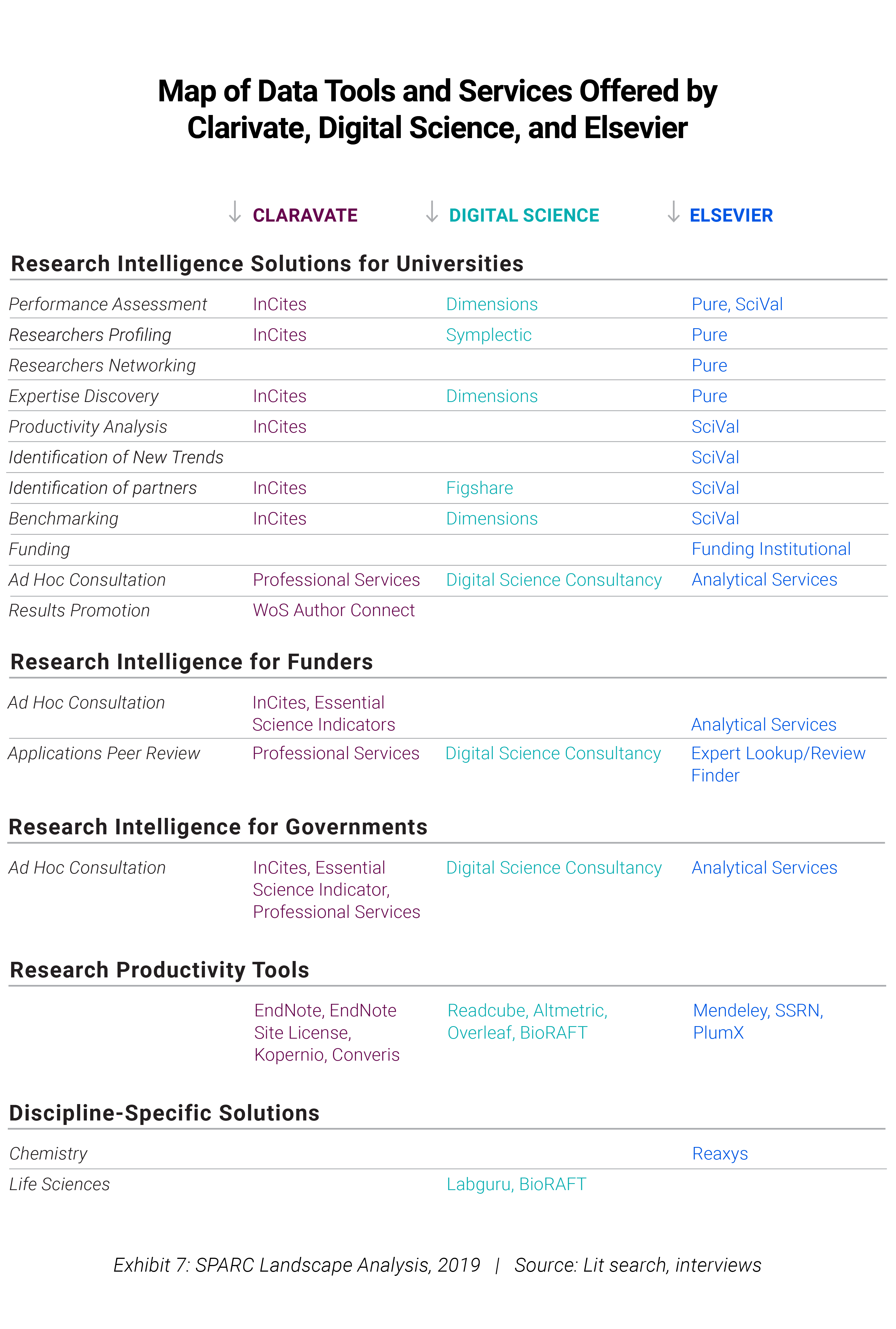
The map we have compiled raises several issues. It is not the purpose of this document to suggest or recommend solutions to the many issues posed by the deployment of these tools, but we believe it is important to raise at least a few questions for the benefit of readers.
-
First, all three companies have targeted customers inside and outside the academic community. This raises an important question for universities: to what extent is it in their interest to share additional data with companies that will likely feed the data (even if in aggregate form, at least some of time) to funding bodies and governmental decision-makers?
-
Second, the use of data is obviously important when assessing productivity and impact, but no algorithm can capture the complexity of some of the judgmental decisions that university administrations and departmental heads are asked to make. Wealthy and well-funded institutions can probably afford to spend the time to evaluate every individual researcher. On the other hand, institutions affected by limitations on budgets will be tempted to give disproportionate weight to tools that can be advertised outside the institution or that affect the behavior of governments and funding bodies. Also, each institution is inherently different in how it wants to weigh quality, performance, and impact. Using a standardized algorithm (that may not even be transparent) could lead to decisions in conflict with the values (and the policies) of any one institution.
-
Third, what is the use of data within these companies once it is made available by research institutions? What degree of privacy is afforded to university and researcher data once it is uploaded to utilize the productivity tools made available? Is this data fed into other businesses within the same company? Is it made available or re-sold to third parties? What would be the response of a commercial vendor to a government request for disclosure or a subpoena?
-
Fourth, some of these businesses effectively text and data mine materials submitted by researchers. What is the licensing agreement underlying these relationships? Do other researchers enjoy similar access rights? One of the issues brewing in the controversy around the boundaries of IP is the limitation demanded by many publishers to the use of third-party software for the purpose of extracting insights. It is debatable whether these demands are strategically sound (we believe they are not, at least in the case of the leading publishers) and whether they make any sense in the case of mining for insights on broad themes, such as the emergence of new disciplines. On the other hand, we find the limitation of text and data mining for conducting scientific research unacceptable, full stop. If text and data mining can be patented, publishers should do so. If they cannot obtain a patent, then demanding that scientific research is conducted exclusively by using their tools is unreasonable.
Once again, this is not (and is not meant to be) a comprehensive list of all the issues posed by the provision of data tools and services outside university libraries. It is also not meant to provide recommendations on possible solutions, which will be articulated at a later stage and in different forums. We expect the list of issues to grow substantially over time, as more people weigh in from their vantage points and based on their experience and concerns.

